Chain State Management
Understanding active state vs archival state in EVM chains, and node configuration options.
When running an EVM-based blockchain (C-Chain or Subnet-EVM L1s), your node stores blockchain state on disk. Understanding the difference between active state and archival state is crucial for choosing the right configuration.
State Sync
State sync is a method of bootstrapping a node by syncing from a state sync snapshot instead of full replay of all historical blocks. This means instead of downloading and replaying all transactions of all blocks since genesis, the node downloads only a latest result of these transactions from the other validators.
This is a faster way to bootstrap a node and is recommended for new validator nodes that do not require archival state.
State sync is enabled by default for the C-Chain. For Avalanche L1s, you can configure it per-chain:
- C-Chain configuration: See C-Chain Config
- Avalanche L1 configuration: See Subnet-EVM Config
To provide this feature, the all Avalanche nodes need to store state sync snapshots every 4000 blocks. This requires additional disk space.
State Types
Your node's storage requirements depend on which type of state you're maintaining:
| Property | Active State | Active State with Snapshots | Archival State |
|---|---|---|---|
| Size (C-Chain) | ~500 GB | ~750 GB - 1 TB | ~13 TB+ (and growing) |
| Contents | Current account balances, contract storage, code | Active state + state sync snapshots for serving peers | Complete state history at every block |
| Required for | Validating, sending transactions, reading current state | Same as Active State, helps other nodes bootstrap | Historical queries at any block height, block explorers, analytics |
| Sync method | State sync (fast, hours) | State sync, then grows over time | Full sync from genesis (slow, days) |
| Maintenance | Periodic state sync snapshot deletion or resync recommended | Periodic pruning or resync recommended | None needed (intentional full history) |
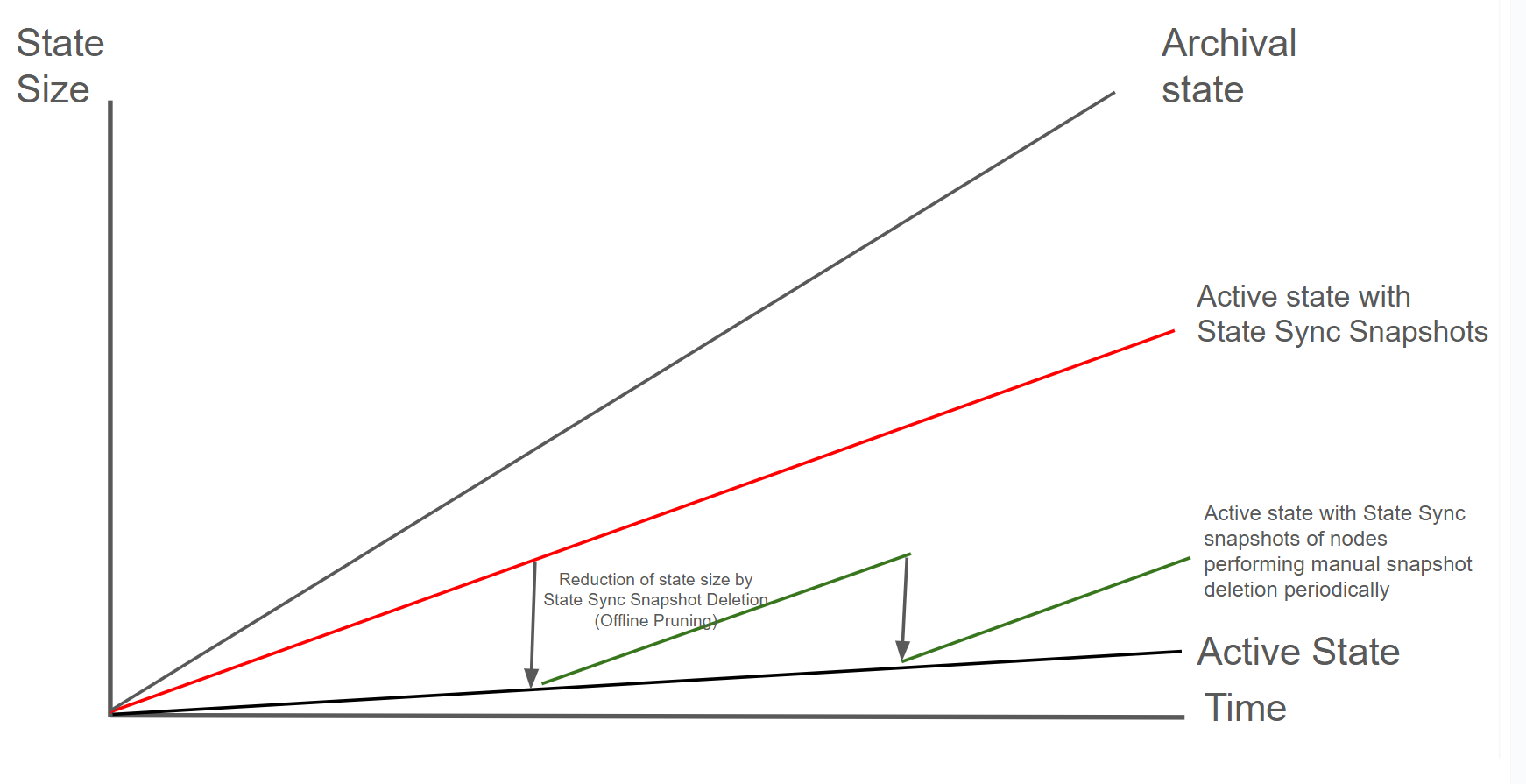
Archival State (gray line)
The archival state includes the complete history of all state changes since genesis. This allows querying historical state at any block height (e.g., "What was this account's balance at block 1,000,000?"). By default Archive nodes are typically only required for block explorers, indexers, and specialized analytics applications. Their disk usage will grow fastest over time.
Most validators and RPC nodes only need active state. Archive nodes are specialized infrastructure for historical data access.
Active State (black line)
The active state represents the current state of the blockchain: all account balances, contract storage, and code as of the latest block. This is what your node needs to validate new transactions and participate in consensus. When you bootstrap with state sync, you start with just the active state. Freshly state-synced nodes will only have the active state.
Active State with State Sync Snapshots (red line)
Nodes with the configuration pruning-enabled: true accumulate not the full historical state but
only the active state and state sync snapshots over time after starting with active state. As blocks
are processed, state sync snapshots are retained every 4000 blocks for serving other
nodes that want to bootstrap via state sync. This causes disk usage to grow beyond the active state
size. Most long-running validators operate in this state.
Future Improvement: Firewood
Firewood is an upcoming database upgrade that will address the issue of state growing too large. This next-generation storage layer is designed to efficiently manage state growth and reduce disk space requirements for node operators.
Active State with periodic snapshot deletion (green line)
Nodes that manually perform some maintenance can reduce their storage requirements by deleting state sync snapshots. This can be achieved by periodically deteleting the state sync snapshots or replacing the node with a freshly-state-synced node.
Monitoring Disk Usage
Track your node's disk usage over time to plan maintenance:
# Check database size
du -sh ~/.avalanchego/db
# Check available disk space
df -h /Consider setting up alerts when disk usage exceeds 80% to give yourself time to plan maintenance.
State Growth Rates
Even with the same configuration, different types of state grow at different rates:
| Growth Type | Rate | Description |
|---|---|---|
| Archival state | ~500 GB/month | Complete history stored at every block |
| Active state + snapshots | ~150-200 GB/month | Active state + Snapshots every 4000 blocks for serving peers |
| Active state | Minimal or <10 GB/month | Current blockchain state only (with pruning enabled) |
Note
State sync snapshots are retained to help other nodes bootstrap. Even if you don't need archival state, these snapshots accumulate over time and increase disk usage.
Node Configuration Matrix
Your node's final state depends on two factors: how you bootstrap and whether pruning is enabled.
| Bootstrap Method | Pruning Disabled | Pruning Enabled |
|---|---|---|
| State Sync | Active + Snapshots (~1TB) To get full archival state, you must do a full sync from genesis. | Active State only (~500GB) |
| Full Sync | Full Archival (~13TB+) | N/A |
Choosing Your Configuration
| Use Case | Bootstrap | Pruning | Result | Disk Size |
|---|---|---|---|---|
| Validator | State Sync | Periodic | Active state, minimal disk | ~500 GB |
| Standard RPC | State Sync | Optional | Current state queries | ~500 GB - 1 TB |
| Archival RPC | State Sync | Disabled | Full state after sync point | ~750 GB - 1 TB |
| Block Explorer / Indexer | Full Sync | Disabled | Complete archival history | ~12.5 TB+ |
Archival RPC vs Block Explorer: An archival RPC started via state sync can answer queries from the sync point forward. For complete historical queries from genesis, you need a full sync.
Is this guide helpful?